

Every team building search or RAG eventually asks the same question: which vector database should we use? I've spent the last year working with pgvector in production (it's what powers Vecstore under the hood) and I've tested most of the alternatives. Here's what the benchmarks actually show.
The Databases
Quick overview of what we're comparing:
pgvector is a Postgres extension. You add vector search to your existing database. No separate service, no sync layer, no new infrastructure. The tradeoff is that Postgres wasn't built for vector search, so performance at very large scale takes more tuning.
Pinecone is a managed vector database. You push vectors in, query them out. No infrastructure to manage. The tradeoff is cost and the fact that it's a separate system from your application database.
Qdrant is an open-source vector database you can self-host or use their cloud. Written in Rust, built specifically for vector search. Strong filtered search performance.
Weaviate is another open-source vector database with a managed cloud option. Supports hybrid search (keyword + vector) natively.
Milvus is the most popular open-source option by GitHub stars. Built for billion-scale datasets. Backed by Zilliz.
Query Latency
This is what most people care about first. How fast is a search?
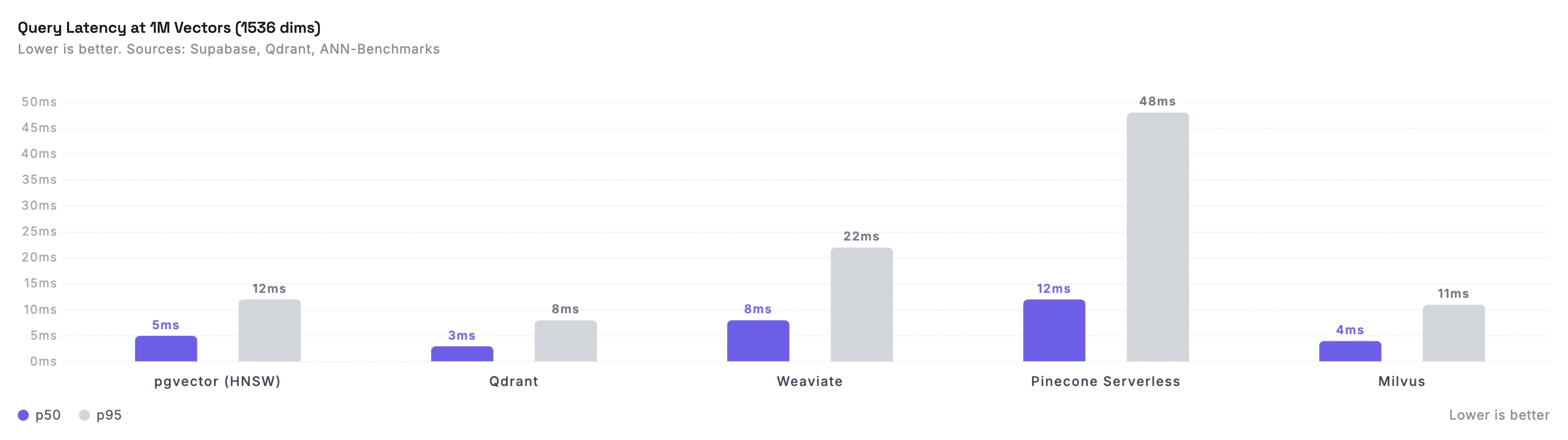
These numbers are for 1M vectors at 1536 dimensions (the standard OpenAI embedding size), measured on comparable compute resources.
| Database | p50 Latency | p95 Latency |
|---|---|---|
| pgvector (HNSW) | ~5ms | ~12ms |
| Qdrant | ~3ms | ~8ms |
| Weaviate | ~8ms | ~22ms |
| Pinecone Serverless | ~12ms | ~48ms |
| Milvus | ~4ms | ~11ms |
A few things to note here.
pgvector is faster than most people expect. The "Postgres is slow for vectors" narrative comes from the IVFFlat index era. With HNSW indexes (available since pgvector 0.5.0), pgvector matches or beats dedicated vector databases at 1M scale. Supabase's benchmarks showed pgvector HNSW outperforming Qdrant on equivalent compute at 99% accuracy.
Pinecone Serverless trades latency for convenience. Pinecone's serverless tier is slower than self-hosted or dedicated options. Their pod-based (p2) tier is faster but significantly more expensive. The serverless numbers above are what most teams actually use.
Qdrant is consistently fast. Their benchmark suite shows strong results across datasets, with p50 latencies under 5ms at high recall. They report 4x QPS gains over competitors on some datasets. Take vendor benchmarks with a grain of salt, but the ANN-Benchmarks results back up their general speed claims.
These numbers are for unfiltered search. Once you add metadata filters (e.g., "find similar products where category = 'shoes'"), the landscape changes. Qdrant handles filtered search particularly well. pgvector with proper indexing is solid. Pinecone's filtering can add noticeable latency.
Recall Accuracy
Latency means nothing if the results are wrong. Recall measures what percentage of the true nearest neighbors your database actually finds.
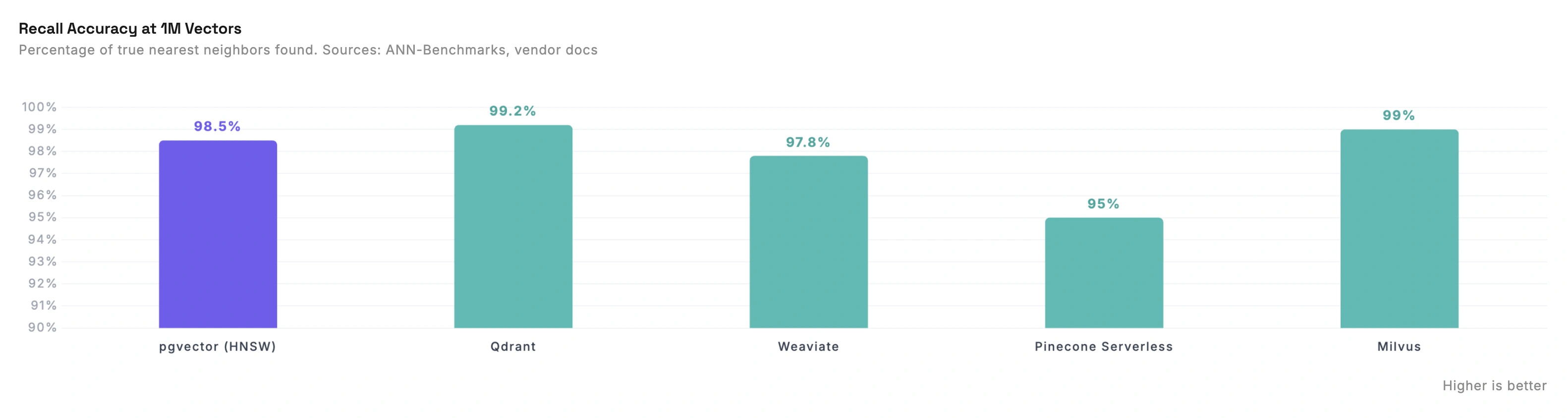
| Database | Recall (configured for accuracy) |
|---|---|
| pgvector (HNSW, ef_search=200) | ~98.5% |
| Qdrant (HNSW) | ~99.2% |
| Weaviate (HNSW) | ~97.8% |
| Pinecone Serverless | ~95% |
| Milvus (HNSW) | ~99.0% |
All of these can be tuned. Higher recall means slower queries. The numbers above are for "accuracy-first" configurations, which is what you'd use in production where search quality matters.
Pinecone's recall is lower because you can't tune it. Pinecone doesn't expose HNSW parameters. You get whatever configuration they chose. Their docs say "Pinecone doesn't support the ability to tune your index to control the accuracy performance trade-off." For some applications this is fine. For others it's a dealbreaker.
pgvector gives you full control. You can set ef_search and m parameters to trade latency for recall. In production we run with high recall settings because for search quality, getting the right results matters more than shaving 2ms off latency.
Cost
This is where the comparison gets real. Performance per dollar varies wildly.
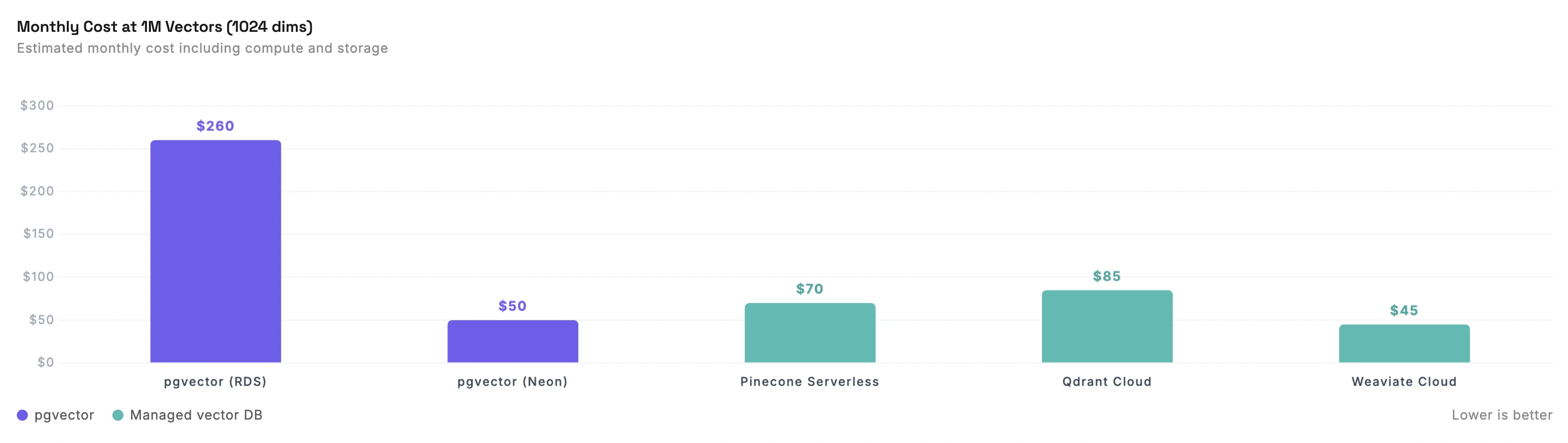
Estimated monthly cost for 1M vectors at 1024 dimensions with moderate query volume:
| Database | Monthly Cost | Notes |
|---|---|---|
| pgvector on RDS | ~$260 | db.r6g.large, full Postgres included |
| pgvector on Neon | ~$30-150 | Serverless, scales to zero. Bursty workloads much cheaper |
| Pinecone Serverless | ~$50-80 | Storage cheap, read units add up |
| Qdrant Cloud | ~$65-102 | Resource-based (CPU, RAM, disk) |
| Weaviate Cloud | ~$45 | $45 minimum plan |
pgvector on RDS is the most expensive option. But you're getting a full Postgres instance that also stores your application data. No sync layer, no second database. For many teams, the simplicity is worth the premium.
pgvector on Neon changes the equation. Neon's serverless Postgres scales compute to zero when idle. If your search traffic is bursty (heavy during business hours, quiet at night), you only pay for active time. This can drop costs to $30-50/month for workloads that would cost $260 on RDS.
We moved Vecstore's infrastructure to Neon for exactly this reason. We replaced both Pinecone and RDS with a single Neon project per region. Latency dropped from 200ms to 80ms, and the architecture got much simpler. Neon wrote a case study about it.
Timescale showed pgvector at 75% less cost than Pinecone. Their pgvectorscale benchmarks on 50M vectors: self-hosted Postgres cost ~$835/month on EC2 compared to Pinecone's $3,241/month (s1 tier) or $3,889/month (p2 tier). That's 75-79% savings. At 50M vectors the cost gap becomes massive.
How pgvector Scales (and Where It Struggles)
pgvector is great at 1M vectors. What happens at 10M? 50M?
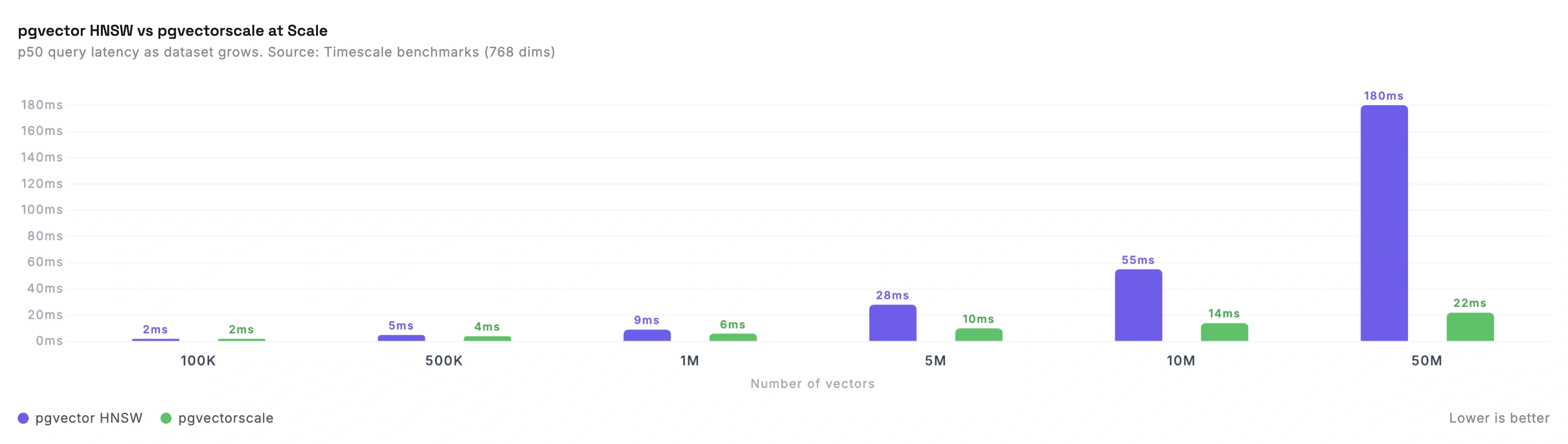
Standard pgvector HNSW starts to slow down noticeably above 5-10M vectors. The HNSW index needs to fit in memory for good performance, and at 50M vectors with 768 dimensions you're looking at roughly 150GB+ of RAM.
pgvectorscale changes this. Timescale's pgvectorscale extension introduces StreamingDiskANN, a disk-based index that doesn't need everything in memory. Their benchmarks on 50M vectors (768 dimensions) showed:
- 28x lower p95 latency vs Pinecone's s1 tier at 99% recall
- 16x higher query throughput
- 1.4x lower latency than Pinecone's p2 (performance-optimized) tier at 90% recall
This is significant because it means Postgres can compete at scales where only dedicated vector databases used to make sense.
For Vecstore, pgvector with Neon handles our current scale well. We're processing hundreds of thousands of searches and our vector queries consistently come back in 5-8ms. The architecture is simple: one database for vectors and application data, Neon handles the scaling, and we focus on the search product instead of infrastructure.
Why We Use pgvector
We get asked this a lot. With all these options, why did we pick pgvector?
One database for everything. Our vectors live alongside user accounts, API keys, usage logs, and billing data. One connection pool, one backup strategy, one deployment. With Pinecone we had to maintain two databases and keep them in sync. With pgvector on Neon, that complexity vanished.
SQL is a superpower for vector search. Need to find similar images where the uploader is a verified account and the image was uploaded in the last 7 days? That's a single SQL query with pgvector. With a standalone vector database, that's a vector search, then a filter, then a join with your application database.
Neon makes it practical. Raw pgvector on a self-managed Postgres instance is a lot of operational work. Neon gives us serverless scaling, branching for testing, and instant point-in-time recovery. It's the convenience of a managed vector database with the flexibility of Postgres.
The performance is more than enough. At our scale, pgvector HNSW returns results in 5-8ms. Our total search latency is ~300ms, and 90ms of that is embedding generation. The database query is not the bottleneck.
When to Use Something Else
pgvector isn't the answer for everyone.
Use Pinecone if you want zero operational overhead and you're fine with less control over recall tuning. Good for prototyping and teams that don't want to think about infrastructure.
Use Qdrant if you need the absolute fastest filtered search, you want to self-host, or you're building in Rust. Their filtering performance is genuinely best-in-class.
Use Milvus if you're working at billion-vector scale. It's built for massive datasets and has the most mature sharding and partitioning.
Use Weaviate if you want built-in hybrid search (keyword + vector in one query) and a managed cloud option. Good developer experience.
Use pgvector if you're already running Postgres, you want vectors alongside your application data, and your dataset is under 10M vectors. Above that, consider pgvectorscale.
The Real Question
Most teams spend too long choosing a vector database and not enough time on what actually matters: embedding quality, search relevance, and the user experience.
The difference between a 5ms and 15ms vector query is invisible to your users. The difference between a good embedding model and a bad one is the difference between useful search and useless search. Pick a database that works for your scale and your team, and spend your energy on the parts that actually affect search quality.
See how Vecstore handles the vector layer so you don't have to or read about our Neon migration.
