

Image search looks simple until you start building it. It's actually five or six separate infrastructure problems, each with its own monthly bill. This post prices out every piece for a real production workload: 1M images, thousands of users, enterprise-level traffic. One person can build it, but you should know what the bill looks like first.
How Image Search Works
At insert time: your backend receives an image, stores it in S3, runs it through a vision model (CLIP, OpenCLIP, SigLIP) to get a vector (an array of 768-1024 numbers representing what the image "means"), and stores that vector in a vector database alongside metadata.
At search time: the user's query (text or image) gets embedded by the same model, sent to the vector database, which returns the closest matching vector IDs. Your backend resolves those IDs to actual image URLs and returns results.
That's the pipeline.
Part 1: GPU Inference
This is where most of the money goes. You need a GPU running a vision model to convert images into vectors, both at insert time and search time.
Choosing a Model
The main options are CLIP ViT-B/32 (fast, lower quality), CLIP ViT-L/14 (solid middle ground), OpenCLIP ViT-H/14 (best open-source quality), and SigLIP SO400M (newest, highest accuracy, slower).
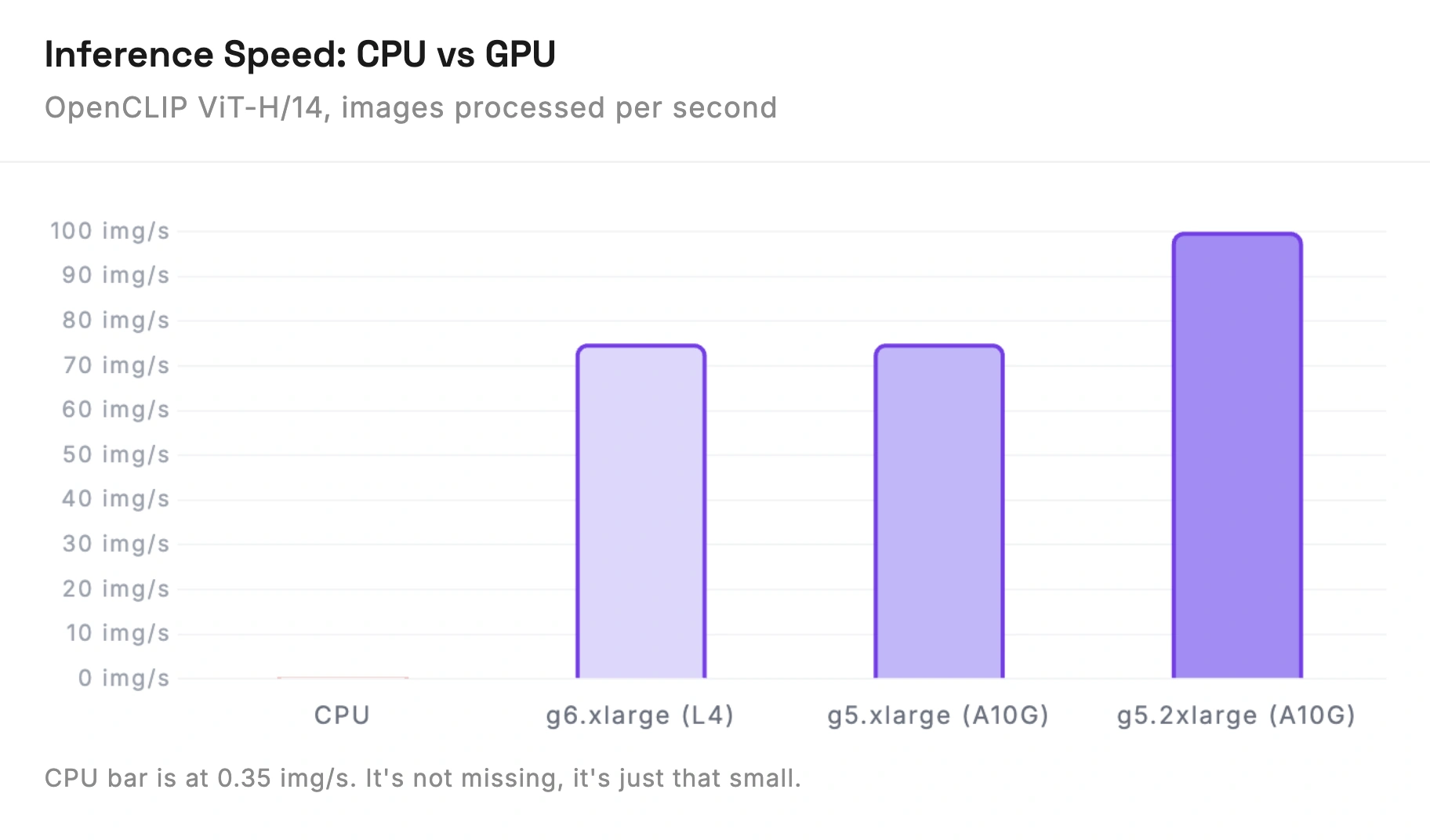
Most people go with OpenCLIP ViT-H/14: 1024-dimensional vectors, 50-100 img/s on an A10G GPU. We'll use that for all calculations.
GPU Instances (AWS)
| Instance | GPU | Hourly | Monthly |
|---|---|---|---|
| g6.xlarge | 1x L4 (24GB) | $0.81 | $588 |
| g5.xlarge | 1x A10G (24GB) | $1.01 | $734 |
| g5.2xlarge | 1x A10G (24GB) | $1.21 | $885 |
| p3.2xlarge | 1x V100 (16GB) | $3.06 | $2,234 |
The g6.xlarge is the best value. Runs OpenCLIP ViT-H/14 at 50-100 images per second.
CPU? No.
OpenCLIP ViT-H/14 on CPU: 0.2-0.5 images per second. One image every 2-5 seconds. With 10 concurrent searches, users wait 20-50 seconds each. Embedding 1M images would take 23-58 days on CPU vs 3-6 hours on GPU.
Spot Instances
Spot cuts GPU costs by 60-70% (g6.xlarge drops to ~$175-235/month). Great for batch embedding. Risky for live search since AWS can terminate with 2 minutes notice.
Concurrency and Enterprise Traffic
50-100 img/s on a single GPU sounds like plenty if you're thinking about a side project. It's not plenty at enterprise scale.
Say your app has 50,000 daily active users, each doing a few searches. That's maybe 200,000-500,000 searches per day. Spread evenly, that's 3-6 queries per second. One GPU handles that fine.
But traffic is never spread evenly. During peak hours (maybe 2-3 hours per day), you might see 20-50 queries per second. If you also have sellers or users uploading new images during those same hours, uploads and searches compete for the same GPU. A spike in uploads tanks your search latency.
At this scale, you realistically need 2 GPU instances: one dedicated to serving search queries, one for processing new uploads and batch work. During peak traffic, you might even want a third.
And this is just 1M images. Enterprise catalogs at 10M+ images with global traffic need even more. The GPU bill scales linearly with query volume.
| Scenario | Setup | Monthly Cost |
|---|---|---|
| Low traffic | 1x g6.xlarge | $588 |
| Medium traffic | 2x g6.xlarge | $1,176 |
| High traffic | 3x g6.xlarge | $1,764 |
| Batch processing (spot) | 1x g6.xlarge spot | +$175-235 |
Part 2: Vector Storage
1M vectors x 1024 dimensions x 4 bytes = 4.1 GB raw. With metadata and indexes, roughly 5-10 GB.
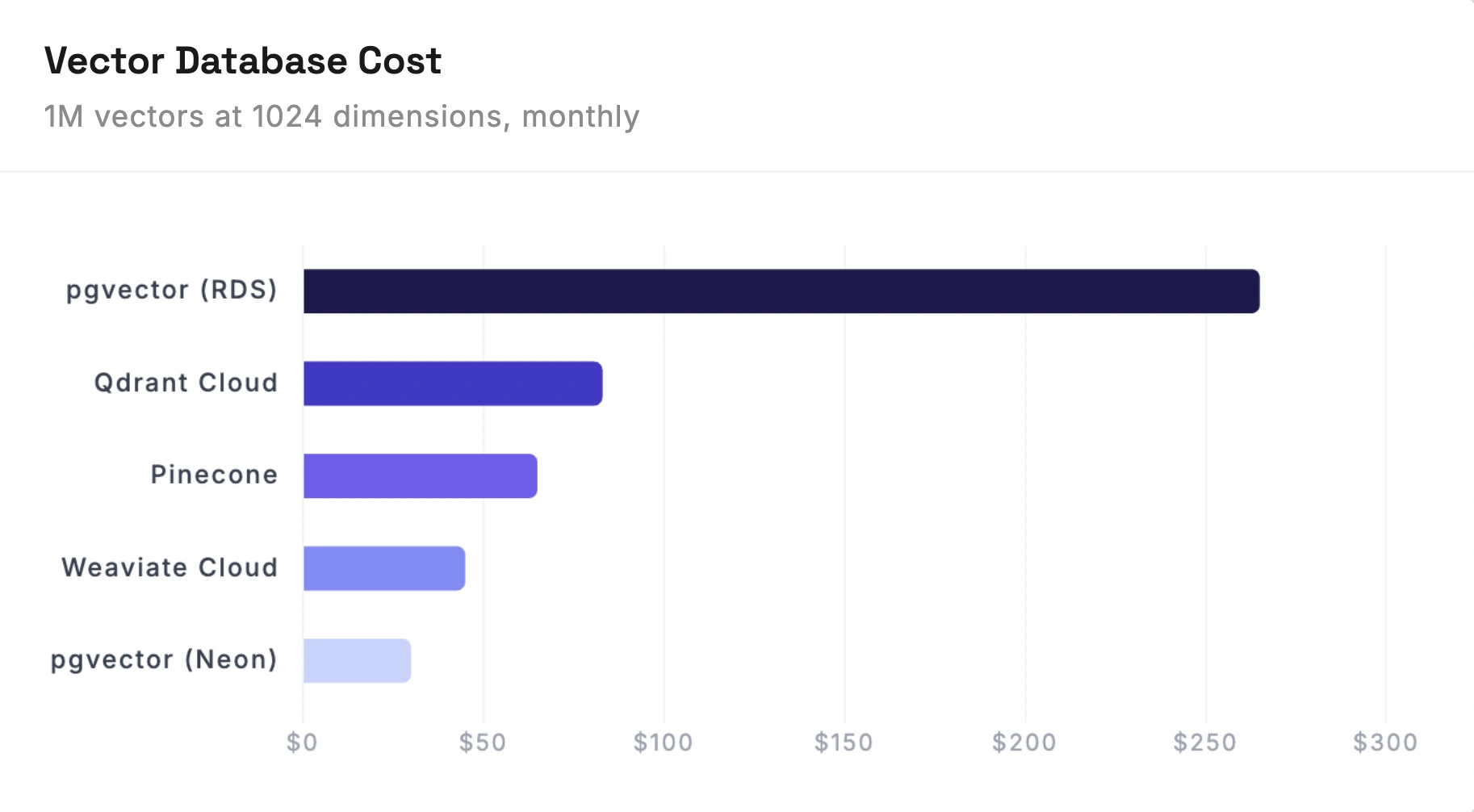
These prices are for 1M vectors. At 10M vectors, the storage costs go up but the real pain is query latency. HNSW indexes get slower as they grow, and you'll likely need to bump your instance sizes or shard across multiple databases. That's when Pinecone and Qdrant start earning their price because they handle that scaling for you.
Part 3: Image Storage and Delivery
1M images at ~500KB each = 500 GB.
| Service | Monthly Cost |
|---|---|
| S3 (500 GB) | $11.50 |
| CloudFront CDN | $0-15 (1 TB free tier is permanent) |
| Total | $11.50-26.50 |
S3 is cheap. This isn't the part of the bill that surprises you. Though at enterprise scale with heavy traffic, CloudFront costs can climb. If you're serving 5 TB/month in images, that's ~$425/month in CDN transfer alone.
Part 4: Backend
The backend mostly routes requests between the GPU and the vector database. It doesn't need to be beefy.
We went with Rust for ours because the memory efficiency and concurrency model means fewer instances. A single Rust server saturates its network before it runs out of CPU. The tradeoff is development speed, but for a service that's mostly routing requests, it's worth it. Most people use Python with FastAPI here, which works fine too. One developer can set either of these up in a day or two.
A t3.small ($15/month) with auto scaling handles this. Set minimum 2 instances behind an ALB so you're never down during deployments, and let it scale up during traffic spikes.
For enterprise traffic (thousands of concurrent users), you'll see the auto scaling group regularly running 4-6 instances during peak. Budget accordingly.
| Scenario | Instances | Monthly Cost |
|---|---|---|
| Low traffic | 2x t3.small + ALB | $57 |
| Medium traffic | 4x avg + ALB | $90 |
| Enterprise | 6x avg + ALB | $120 |
Part 5: Embedding 1M Images
Before search works, you embed every image. 1M images through OpenCLIP ViT-H/14 on a g6.xlarge:
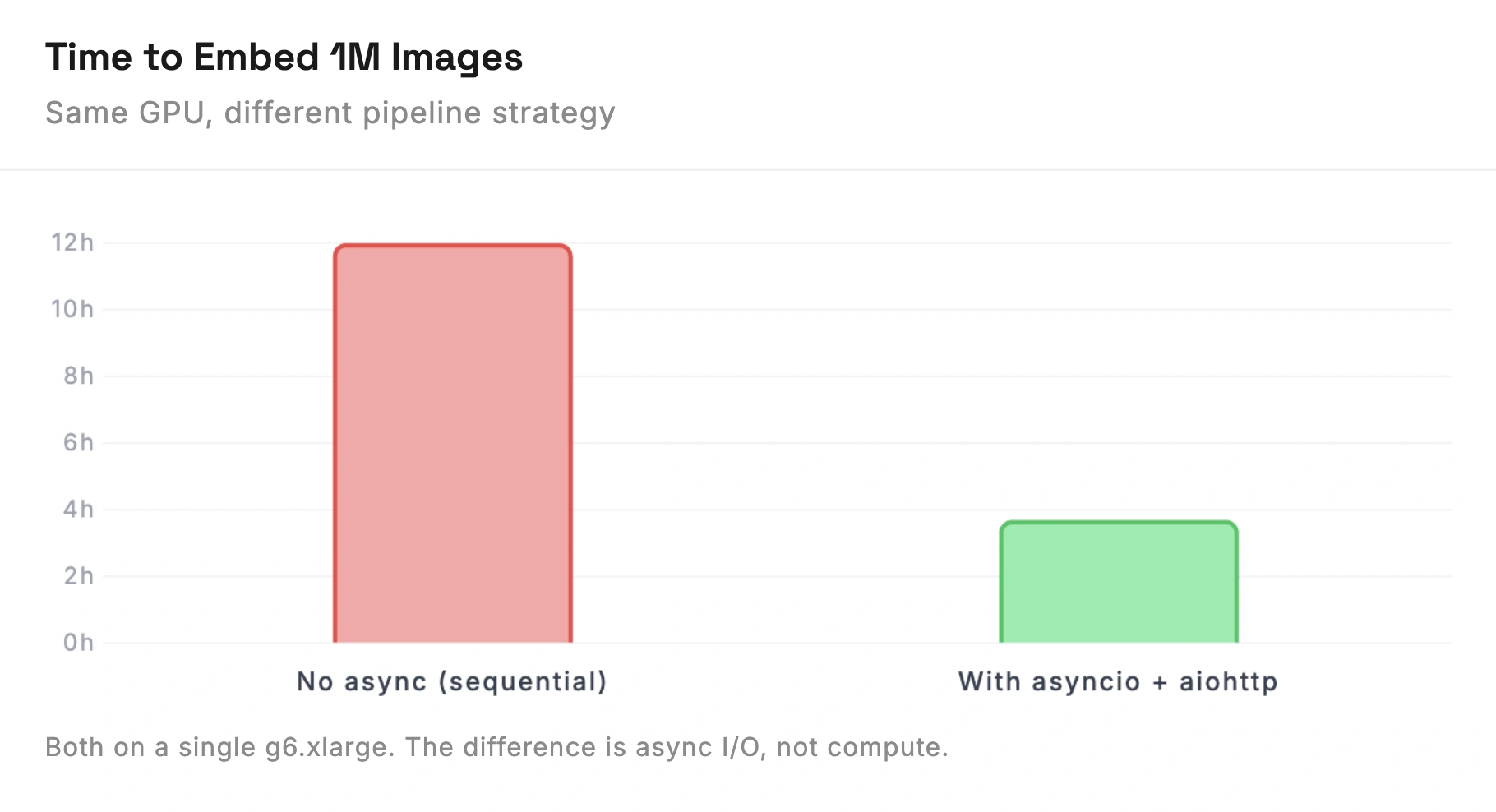
- Time: ~3.7 hours
- Cost: ~$3.00 (under $1 on spot)
The compute is cheap. The bottleneck is I/O. If you process images one at a time, the GPU sits idle waiting for downloads between each inference.
Python with asyncio and aiohttp solves this. Download images in batches of 100-200 concurrently, feed each batch to the GPU, batch-insert vectors into your database. This keeps the GPU busy. Without async batching, the same 3.7-hour job takes 12+ hours.
Good weekend project. Set up the async pipeline, kick off the batch, go do something else while it runs. Just don't run it through your production backend. Spin up a dedicated instance for the initial load.
The Full Bill
Two scenarios: a moderate-traffic app and an enterprise workload.
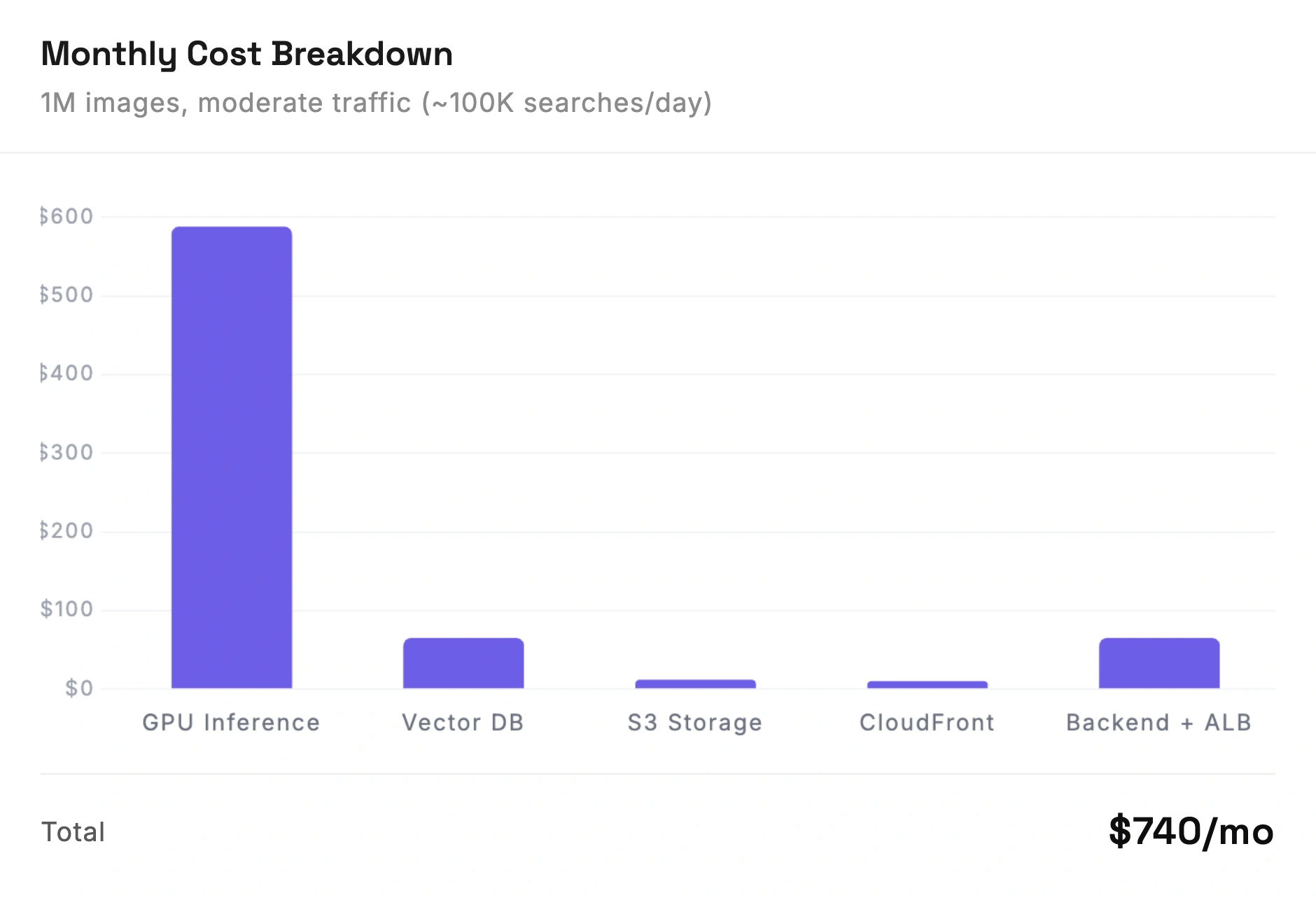
$740/month for moderate traffic (~100K searches/day). One GPU instance, Pinecone for vectors, small auto-scaling backend. The GPU eats 80% of the budget.
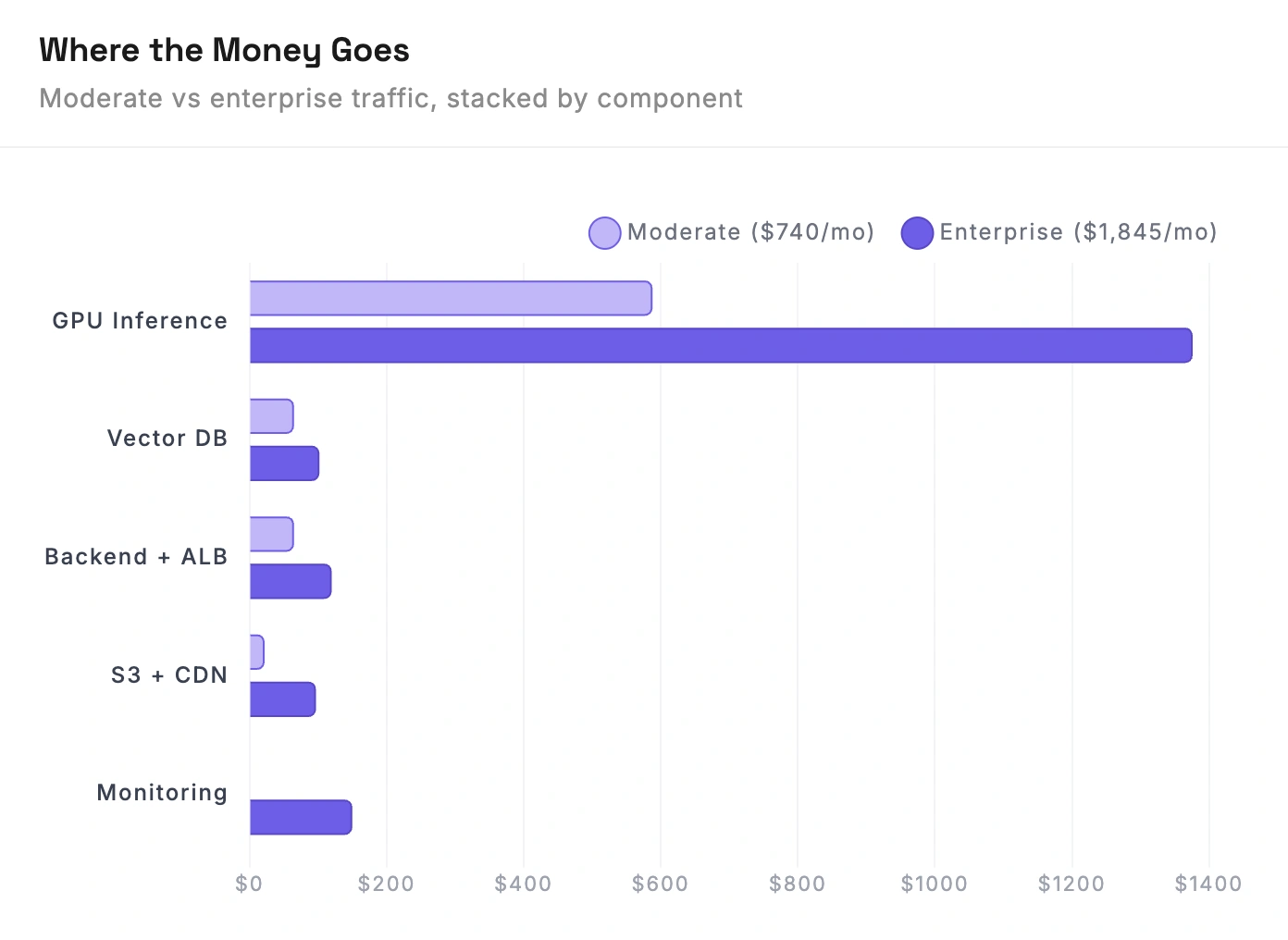
At enterprise scale (~500K+ searches/day), the bill jumps to $1,845/month. The GPU cost more than doubles (you need 2 instances plus a spot instance for batch work), and you're adding monitoring, more CDN bandwidth, and a beefier backend.
What's Not Included
Your time. This is totally buildable by one developer. The pipeline, the GPU setup, the vector database, the backend, all of it. Expect 2-4 weeks for the initial build if you're doing it solo. The ongoing maintenance is the real time sink: model upgrades mean re-embedding everything, traffic spikes mean debugging capacity issues, and things will break at inconvenient times.
Scaling beyond 1M. At 10M images, you're looking at roughly 3-5x these costs. GPU inference scales linearly, vector database costs go up, and the backend needs more capacity. The architecture stays the same but everything gets bigger.
Is It Worth It?
$740/month for moderate traffic is very doable, even for a solo developer. You can build this over a few weekends, it's well-documented technology, and the architecture is straightforward.
At enterprise scale ($1,845/month and up), it's still reasonable if image search is a core part of your product. That's less than the cost of one engineer's monthly salary, and you're getting a real production system.
Where it starts to hurt is the time. Not the building, the maintaining. Every CLIP model update, every scaling event, every outage. That's the ongoing tax. Whether you're fine paying that tax depends on how central image search is to what you're building.
Either way, now you know what the bill looks like.
